4. Resultados
Esta sección presenta los resultados de la evaluación independiente de BDTI para los ejemplos de implementación de coma flotante con los solucionadores de Cholesky y QR.
En todos los diseños se ha utilizado el DSP Builder Advanced Blockset v12.0 de Altera, con MathWorks versión R2011b, y se ha creado mediante el software de diseño Quartus II v12.0 SP1. Las simulaciones de RTL se llevaron a cabo con ModelSim 10.1. Los diseños se efectuaron para dos FPGA de 28 nm de Altera: el dispositivo de gama alta y tamaño medio Stratix V 5SGSMD5K2F40C2 y el dispositivo de gama media Arria V 5AGTFD7K3F40I3N. La FPGA Stratix V utilizada en este análisis incorpora 345,2K ALUT, 1.590 multiplicadores de precisión variable de 27x27 bit y 2.014 bloques de memoria M20K. La FPGA Arria V incorpora 380,4K ALUT, 1.156 multiplicadores de precisión variable de 27x27 bit y 2.414 bloques de memoria M10K. Las plataformas de hardware utilizadas para la evaluación fueron el DSP Development Kit, Stratix V Edition, y el Arria V FPGA Development Kit. También se usó el software ModelSim para una configuración con el fin de evaluar la facilidad de manejo de la herramienta desde el entorno Simulink.
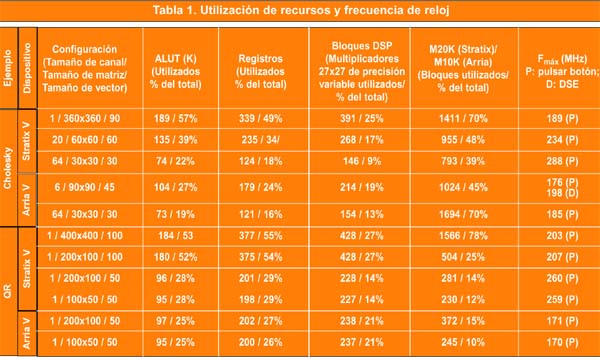
En total se simularon once casos que se realizaron para ambos diseños en los dos dispositivos. Se guardaron los resultados en cuanto a utilización de recursos, prestaciones y precisión para cada caso. La Tabla 1 indica la utilización de recursos y la frecuencia de reloj alcanzada para los solucionadores de Cholesky y QR para cada configuración. El diseño del solucionador de Cholesky proporciona un parámetro de tamaño máximo de matriz. Durante la ejecución se pueden utilizar tamaños de la matriz más pequeños que el tamaño máximo de diseño. Para los resultados de la utilización de recursos presentados en la Tabla 1, se sintetizó cada configuración con el parámetro de tamaño máximo de matriz igual al tamaño de la matriz evaluado con el fin de obtener los recursos reales consumidos por el tamaño de matriz indicado. Los recursos utilizados por los bloques de estímulos no se han incluido en los totales. Conviene destacar que ninguna de las configuraciones evaluadas en este artículo utilizó las FPGA hasta su máxima capacidad. Para lograr la mejor Fmax en un tiempo razonable de síntesis y emplazamiento-enrutamiento en el software Quartus II se aplicaron los mismos parámetros de optimización previamente establecidos para cada diseño con el fin de mejorar la velocidad. Escogimos la configuración 6/90x90/45 para el ejemplo de diseño Cholesky para ejecutar el Design Space Explorer (DSE) del software Quartus II con el fin de hallar la mejora de la velocidad y el tiempo que necesitó la síntesis en comparación con el modo pulsar botón. En este caso se registró una mejora de la velocidad del 12,5%, si bien el tiempo de ejecución del software Quartus II aumentó de 2 horas a 7,5 horas para sintetizar el diseño.
La utilización de recursos de FPGA coincide con las previsiones para los diseños evaluados. El uso de la memoria está dominado por el almacenamiento en memoria y es proporcional al tamaño de la matriz y al número de canales para un diseño multicanal. El uso de bloques DSP aumenta linealmente con el tamaño del vector. El multiplicador vectorial exige 4 bloques DSP de precisión variable por multiplicación de coma flotante de valor complejo de 27 bit x 27 bit. Para un tamaño de vector determinado de 60 valores de coma flotante complejos se necesitan 240 bloques DSP para el generador de productos escalares.
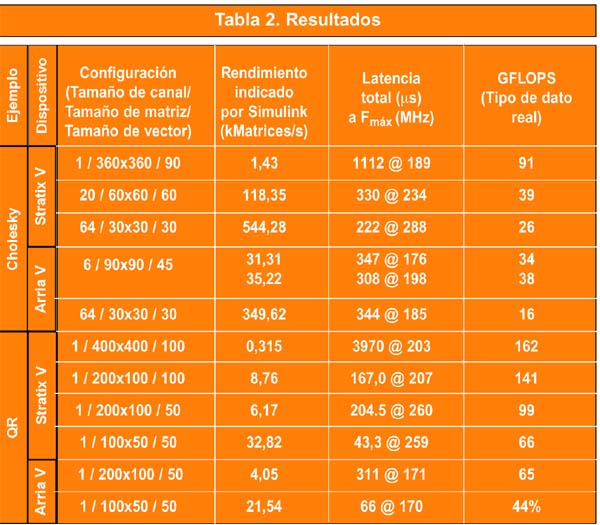
La Tabla 2 ofrece las prestaciones de los solucionadores de Cholesky y QR para todas las configuraciones. Las prestaciones para cada caso se indican en la Fmax de la Tabla 1. El rendimiento se calcula dividiendo Fmax entre los ciclos consumidos por la ejecución del subsistema progresivo del solucionador. Dado que el subsistema de sustitución regresiva se ejecuta en paralelo y con una menor latencia que el subsistema progresivo, el rendimiento total no se ve afectado. Para el rendimiento del solucionador de Cholesky multicanal, este resultado se multiplica por el número de canales que se procesan en paralelo (parámetro “Tamaño de canal” en la Tabla 2). La latencia total para cada caso se calcula al dividir los ciclos totales que tarda la ejecución de los subsistemas progresiva y regresiva entre Fmax. La elección del tamaño del vector relativo al tamaño de la matriz es un compromiso que depende de la aplicación. Si el tamaño del vector es mucho más pequeño que el tamaño de la matriz, el diseño será eficiente en el uso de recursos a expensas de la latencia, tal como se indica para las configuraciones con un tamaño de matriz 200x100 del solucionador QR con diferentes tamaños de vector.
Las mejoras que introduce el diseño de Cholesky multicanal en el diseño multicanal ya se analizaron en el artículo anterior de BDTI. En la implementación de un solo canal, las latencias como las propias del acumulador de coma flotante se vieron parcialmente ocultadas por la reconfiguración del orden de proceso en el algoritmo. Tal como se explica en la referencia [1], la eficiencia de la implementación de un solo canal dependía principalmente de los tamaños de la matriz y del vector. Si se observa la columna de rendimiento en la Tabla 2, la implementación multicanal presenta importantes ventajas en cuanto a eficiencia de proceso, sobre todo para matrices y vectores de menor tamaño. El proceso multicanal mejora el rendimiento al ocultar por completo las latencias de implementación descritas en la Sección 2 de este artículo. Para tamaños determinados de la matriz y del vector, una implementación multicanal proporcionará un pico de rendimiento más elevado que su homólogo de un solo canal.
La última columna de la tabla ofrece el número de operaciones de coma flotante de datos reales por segundo en unidades de 109 (GFLOPS) para cada configuración. El número de operaciones que necesita cada solucionador depende del algoritmo de descomposición utilizado. Las cifras indicadas se obtienen de la implementación real de los algoritmos del solucionador de Cholesky y QR en formato de datos complejos de coma flotante en las dos FPGA utilizadas para esta evaluación. Para el solucionador de Cholesky, el número de operaciones de coma flotante de datos reales es aproximadamente el término de segundo orden 4n3/3 + 12n2, mientras que para el solucionador QR se utiliza 8mn2 + 6,5m2 + mn.
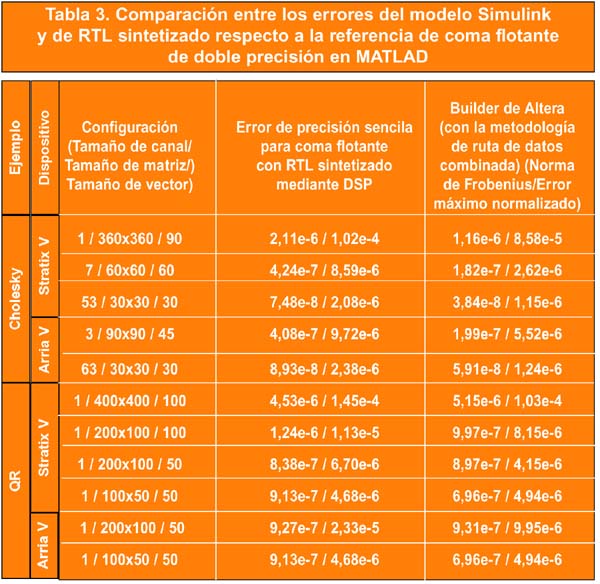
La Tabla 3 indica las prestaciones de los solucionadores de Cholesky y QR desde el punto de vista del error, para la simulación con Simulink y la implementación del diseño mediante las tarjetas de desarrollo de hardware con operaciones de coma flotante de precisión sencilla.
El error se calcula por comparación de la salida de cada simulación de Simulink y de la plataforma de hardware con la referencia de coma flotante de doble precisión para los vectores solución x generador por MATLAB. Para los casos del solucionador de Cholesky multicanal, solo se indican por razones de brevedad las prestaciones desde el punto de vista del error de un solo canal escogido de forma aleatoria. Aunque el error depende de los datos de entrada, por término medio la implementación RTL aprovecha la metodología de la ruta de datos combinada y logra una precisión estadísticamente igual o superior a la implementación de precisión sencilla del estándar IEEE 754 como se demuestra por comparación de la Norma de Frobenius en las columnas (4) y (5) de la Tabla 3.
Utilizamos la Norma de Frobenius para obtener una medida de la magnitud de error total en el vector resultante que se expresa así:
||E||F = ÷SN = 0 |ei|2
i
Donde N es el tamaño del vector, e es el vector diferencia entre la x observada y su referencia generada por MATLAB, e i es el índice de los elementos en el vector e. El error máximo normalizado se expresa:
max (|(xi-obs - xi-ref)/xi-ref|)
i
5. Conclusiones
Se ha evaluado en este artículo un nuevo método para implementar algoritmos DSP de coma flotante con FPGA que utilizan el flujo de diseño del DSP Builder Advanced Blockset de Altera. Este flujo de diseño incorpora el DSP Builder Advanced Blockset de Altera, el paquete de herramientas de software Quartus II de Altera y el simulador Simulink, así como MATLAB y Simulink de MathWorks. Este método permite que el diseñador trabaje al nivel de comportamiento algorítmico en el entorno Simulink. El paquete de herramientas combina e integra las etapas de modelación y simulación del algoritmo, la generación de RTL, síntesis, emplazamiento-enrutamiento y verificación del diseño dentro del entorno Simulink. Esta integración permite agilizar el desarrollo y una rápida exploración del espacio de diseño tanto a nivel algorítmico como de la FPGA, y logra reducir el esfuerzo general dedicado al diseño. Una vez modelado y depurado el diseño a alto nivel, el diseño se puede sintetizar y trasladarlo a una FPGA de Altera.
Para llevar a cabo esta evaluación, los ejemplos de diseño fueron los solucionadores de Cholesky y QR de coma flotante IEEE 754 de datos complejos de precisión sencilla modelados en Simulink mediante el DSP Builder Advanced Blockset de Altera. El ejemplo de diseño de mayor tamaño que se evaluó fue un solucionador QR para una matriz de coma flotante de valores complejos de tamaño 400x400 y un tamaño del vector de 100. Cuando se ejecuta a 203 MHz este ejemplo procesa 162 GFLOPS. Los valores de GFLOPS indicados en la Tabla 2 corresponden a la implementación real de los algoritmos del solucionador de Cholesky y QR en un formato de datos complejos de coma flotante en las dos FPGA. Para que la comparación con otras plataformas de la competencia sea válida se deberían implementar los mismos algoritmos en estas plataformas y se deberían medir sus prestaciones. Todos los resultados indicados se han logrado con la herramienta DSP Builder Advanced Blockset de Altera sin optimización manual o planificación base. Tomando como punto de partida un diseño de alto nivel basado en bloques en Simulink, la herramienta se encargó automáticamente de segmentar, generar el código RTL y sintetizar el diseño para obtener velocidades utilizables así como el uso de recursos. El flujo de diseño de coma flotante simplifica el proceso de implementación de algoritmos DSP de coma flotante complejos en una FPGA al unir las herramientas en una sola plataforma. Con esta metodología de ruta de datos combinada se implementan rutas de datos complejas de coma flotante con un mayor nivel de prestaciones y de eficiencia que con anterioridad.
El nuevo método analizado en este artículo también exige una significativa curva de aprendizaje para la utilización de DSP Builder Advanced Blockset. Esto se cumple especialmente para un diseñador que no esté familiarizado con MATLAB y Simulink. El método de introducción del diseño basada en bloques puede suponer una dificultad inicial para un diseñador de hardware tradicional. Además, para aprovechar las ventajas que ofrece el método de diseño basado en bloques respecto a RTL escrito a mano el diseñador debe dar otros pasos para crear el modelo Simulink. Por ejemplo, para realizar pruebas con diferentes tamaños de matrices y vectores, tal como se ha hecho con los dos ejemplos de diseño descritos en este artículo, el modelo Simulink se estructuró para incorporar un diseño determinado por parámetros con el fin de explorar las diversas configuraciones de diseño.
En la actualidad los diseñadores que utilizan el DSP Builder Advanced Blockset se deben limitar a los elementos que suministra el blockset (paquete de bloques) para lograr unas prestaciones optimizadas. Los elementos del DSP Builder Blockset estándar no están optimizados con el compilador de coma flotante ni se pueden combinar con el Advanced Blockset al mismo nivel jerárquico. Los bloques de HDL codificados a mano solo se pueden importar en el Standard Blockset. Además, el DSP Builder Advanced Blockset se orienta a implementaciones de DSP y puede tener un uso limitado a diseños que incluyan un potente control y máquinas de estado.
La siguiente versión de DSP Builder Advanced Blockset, cuya disponibilidad está prevista para finales de 2012, incluirá extensiones de coma flotante. El diseñador ya no se verá limitado a los dos formatos de precisión sencilla y doble precisión de IEEE 754, sino que podrá optar entre un total de siete precisiones diferentes de 16 a 64 bits (exponente más mantisa). Con la utilización del nuevo bloque Enhanced Precision Support en el DSP Builder Advanced Blockset, el diseñador puede escoger el ancho de los datos que mejor se adapte a su aplicación.
Autor:
Por el equipo de Berkeley Design Technology, Inc. Octubre 2012
6. Referencias
[1] Berkeley Design Technology, Inc., 2011. “An Independent Analysis of Altera’s FPGA Floating-point
DSP Design Flow”.
Disponible para su descarga en http://www.altera.com/literature/wp/wp-01166-bdti-altera-floating-point-dsp.pdf
[2] S.S. Demirsoy, M. Langhammer, 2009. “Fused datapath floating point implementation of Cholesky decomposition”. FPGA’09, February 2009.
Más información o presupuesto
Articulos Electrónica Relacionados
-
QUÉ SON LOS SOM Y LOS SoC
El concepto de System-on-Modules (SOM) surgió a partir de los Blade Servers. Estos servidores delgados se crearon con el objetivo de ahorrar espacio de almacena...
Diseño
-
Herramienta para evitar los er...
Esta herramienta para ingenieros, diseñadores y cualquier otra persona involucrada en el diseño o proceso de producción de una PCB, identifica algunos errores c...
Diseño
-
Las soluciones de gestión de p...
Las iniciativas ecológicas siguen transformando los diseños de sistemas electrónicos de potencia en aplicaciones industriales, aeroespaciales y de defensa, y es...
Diseño
-
Cypress anuncia la actualizaci...
Cypress Semiconductor Corp. anuncia a la Versión 2.0 de su revolucionario Entorno de Diseño PSoC Creator™ para las familias de sistemas en chip programabl...
Diseño
-
Dragonfly Pictures, Inc. desar...
Los drones de ala fija ofrecen la posibilidad de atravesar el espacio aéreo a alta velocidad pero no están capacitados para su uso en aplicaciones que exijan vu...
Diseño
-
¿Los transductores híbridos so...
Se prevé que surjan mercados para sensores capaces de ofrecer tiempos de respuesta a partir de 100ns y unas frecuencias de corte sin precedentes por encima de 1...
Diseño
-
Libro del conocimiento sobre C...
RECOM ha lanzado la más reciente publicación de su serie «Libros del Conocimiento» con la CEM como tema. Escrito por Steve Roberts, Director de Innovación de RE...
Diseño
-
Libros electrónicos formativos...
Mouser Electronics, Inc continúa ayudando a los ingenieros ofreciéndoles nuevos recursos técnicos. Este año ha publicado más libros electrónicos, colaborando co...
Diseño
-
Kits de desarrollo reComputer ...
Mouser ya dispone de los kits de desarrollo reComputer Jetson 20-1 Xavier NX y reComputer Jetson 10-1 Nano de Seeed Studio.
stos kits de desarrollo cuentan c...
Diseño