Arquitectura
Solucionador de Cholesky
En nuestro ejemplo de diseño, se implementa el solucionador de Cholesky en la FPGA como dos subsistemas que trabajan en paralelo de forma segmentada. El primer subsistema ejecuta la descomposición de Cholesky y la sustitución progresiva (pasos 1 y 2 en el recuadro El solucionador de Cholesky). El segundo subsistema ejecuta la sustitución regresiva (paso 3 en el mismo recuadro).
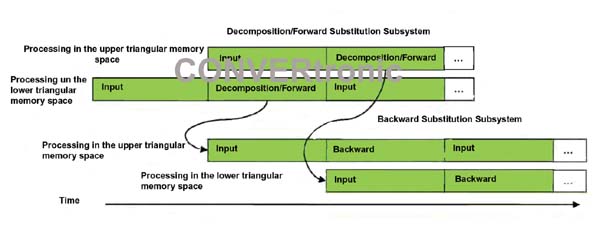
 Como la matriz de entrada es Hermitiana y la descomposición genera matrices triangulares complejas de transposición conjugada, el uso de la memoria se optimiza cargando únicamente la mitad triangular inferior de la matriz de entrada A y sobreescribiéndola al generar la matriz triangular inferior L. Ambos subsistemas están segmentados y utilizan una etapa de entrada y una etapa de proceso para permitir que el proceso se realice en una área de la memoria mientras la otra mitad se emplea para cargar datos nuevos. La salida de la descomposición y la etapa de sustitución progresiva van a la etapa de entrada de la sustitución regresiva, tal como muestra la Figura 2.
Como la matriz de entrada es Hermitiana y la descomposición genera matrices triangulares complejas de transposición conjugada, el uso de la memoria se optimiza cargando únicamente la mitad triangular inferior de la matriz de entrada A y sobreescribiéndola al generar la matriz triangular inferior L. Ambos subsistemas están segmentados y utilizan una etapa de entrada y una etapa de proceso para permitir que el proceso se realice en una área de la memoria mientras la otra mitad se emplea para cargar datos nuevos. La salida de la descomposición y la etapa de sustitución progresiva van a la etapa de entrada de la sustitución regresiva, tal como muestra la Figura 2.
La parte principal de la descomposición consiste en el generador de productos escalares complejos (también denominado multiplicador vectorial), que calcula las ecuaciones (3) y (4). Para el dispositivo Stratix V se utiliza un tamaño de vector (VS) de hasta 90 elementos de datos complejos, mientras que para el dispositivo Arria V se implementa un tamaño de vector de hasta 45 elementos de datos complejos. El tamaño del vector corresponde al número de lecturas de memoria en paralelo que se necesitan para proporcionar al generador de productos escalares un nuevo conjunto de datos para cada ciclo de reloj, y por tanto determina la anchura y la partición de la memoria de doble puerto integrada en el chip. Por razones relacionadas con la implementación, el almacenamiento de una matriz de un tamaño determinado se divide en bancos de memoria techo (N/VS), donde el techo (VS) es la función techo y N es el tamaño de la matriz.
El diseño del solucionador de Cholesky es de tipo multicanal. El número máximo de canales es un parámetro del tiempo de compilación y se ve limitado únicamente por la memoria disponible en el dispositivo. La partición de la memoria es idéntica a la implementación en un solo canal con la diferencia de que se realiza un determinado número de copias de la misma estructura.
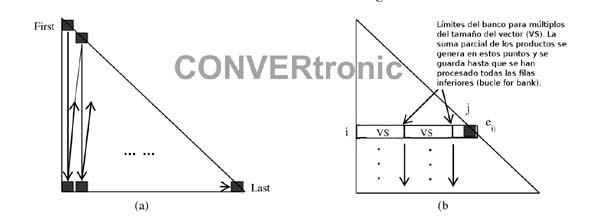
La descomposición se lleva a cabo elemento a elemento, columna a columna, empezando por la esquina superior izquierda y siguiendo en sentido vertical con forma de zigzag, para acabar en la esquina inferior derecha de la matriz tal como muestra la Figura 3(a). Primero se calcula el elemento diagonal de cada columna, seguido por todos los elementos no diagonales situados por debajo en la misma columna y antes de pasar al elemento diagonal en la parte superior de la siguiente columna a la derecha. El programa de eventos e iteraciones se controla con un bucle for anidado de cuatro niveles. El bucle exterior implementa el proceso en el sentido de la columna; el segundo bucle implementa un proceso en el sentido del banco; el tercer bucle interior procesa las filas; y el bucle más interior procesa los diferentes canales. La ubicación del proceso de canal como el bucle más interior convierte en la práctica al acumulador de coma flotante en un acumulador de tiempo compartido y oculta mejor su latencia. El bloque NestedLoops de DSP Builder Advanced Blockset integra hasta tres bucles anidados en un solo bloque de proceso, lo cual acelera la implementación y logra que aproveche los recursos de forma más eficiente si se compara con una función similar implementada como tres bloques for-loop por separado. El bloque extrae las intrincadas señales de control de bucle, reduce los tiempos de diseño y depurado, y hace que la estructura del bucle sea más legible
 El generador productos escalares trabaja con las filas de la matriz y calcula multiplicaciones hasta el tamaño del vector en el término de suma de las ecuaciones (3), (4) y (6) simultáneamente en un solo ciclo. Se emplea una estructura de memoria circular a la entrada del generador de productos escalares en ciclos de filas de las múltiples matrices de entrada.
El generador productos escalares trabaja con las filas de la matriz y calcula multiplicaciones hasta el tamaño del vector en el término de suma de las ecuaciones (3), (4) y (6) simultáneamente en un solo ciclo. Se emplea una estructura de memoria circular a la entrada del generador de productos escalares en ciclos de filas de las múltiples matrices de entrada.
Para productos escalares más cortos que el tamaño del vector, los términos no utilizados quedan enmascarados y no se incluyen en la suma. Para productos escalares más largos que el tamaño del vector, las sumas parciales de los productos se calculan y se guardan en los límites del banco hasta la suma de todos los bancos que están disponibles para un elemento determinado en la fila correspondiente para una suma final, tal como indica la Figura 3(b). La suma de las salidas del banco se lleva a cabo en un solo bucle de acumulador mediante el bloque se sumador de coma flotante de DSP Builder Advanced Blockset. El bucle de realimentación tiene una latencia de 13 ciclos. Al intercambiar el lazo for Banks y el lazo for Rows relativo al orden que estaría presente de forma tradicional en una implementación de software, y al añadir proceso multicanal, la latencia del acumulador de coma flotante se oculta y mejora la utilización del hardware.
El DSP Builder Advanced Blockset calcula automáticamente los retardos de bucle para afrontar este tipo de latencia. Se puede configurar la herramienta de manera que calcule y ocupe el retardo mínimo al comprobar el cuadro Minimum delay en el bloque Loop Delay. A las rutas que provocan retardos idénticos se les puede asignar un número de grupo de equivalencia y la herramienta asignará a continuación el mismo valor de retardo a todos los miembros del grupo. Aunque no se aplica en los ejemplos evaluados en este artículo, el DSP Builder Advanced Blockset proporciona un acumulador de coma flotante específico para la aplicación en el cual el usuario puede personalizar el acumulador para optimizar su velocidad y los recursos necesarios configurando parámetros como el tamaño máximo de entrada y la precisión de acumulación necesaria. Este bloque permite una acumulación de un solo ciclo por muestra de un solo flujo de números de coma flotante con una elevada frecuencia de reloj.
El segundo subsistema realiza la sustitución regresiva. Este subsistema cuenta con sus propios bloques de memoria de entrada y salida. Al igual que el subsistema de sustitución progresiva de Cholesky, se segmenta en una etapa de entrada y en la etapa de proceso. Dado que la complejidad de la sustitución regresiva es del orden de N2 si se compara con N3 para la descomposición, no se emplea el proceso vectorial para el producto escalar. En lugar de ello se utiliza un solo multiplicador complejo para el producto escalar, que basta para seguir el paso de la descomposición de Cholesky y el subsistema de descomposición progresiva.
Autor:
Por el equipo de Berkeley Design Technology, Inc. Octubre 2012
(Continua en el mes de Marzo)
Articulos Electrónica Relacionados