Solucionador QR
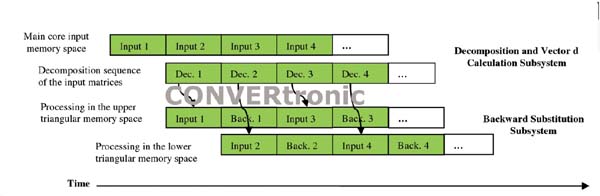
La descomposición y el solucionador QR se implementan como dos subsistemas que funcionan en paralelo de forma segmentada tal como indica la Figura 4. El primer subsistema ejecuta los pasos 1 y 2 en el recuadro titulado El solucionador QR, en el cual el segundo subsistema ejecuta la sustitución regresiva en el paso 3. La sustitución regresiva es idéntica a la utilizada en el solucionador de Cholesky.
A diferencia de Cholesky, donde se implementan las ecuaciones (1) a (6) como un solo lazo anidado de cuatro niveles, el solucionador QR emplea una sola máquina de estado finito (finite state machine, FSM) para ciclos de las cuatro operaciones principales: hallar el cuadrado de la magnitud de un vector en la ecuación (2), el producto escalar de dos vectores en la ecuación (4), la sustracción de un producto escalar de un vector en la ecuación (6) y el producto escalar en la ecuación (7) para hallar el vector d. El bloque NestedLoop en el DSP Builder Advanced Blockset se utiliza en todas las fases de la FSM para generar todas las señales de control eventos para la ruta de datos.
El bloque de proceso común en las cuatro operaciones antes citadas es el generador del producto escalar. Para aumentar las prestaciones se utiliza el proceso vectorial con el fin de calcular el producto escalar. De forma parecida al diseño de Cholesky, el tamaño del vector es un parámetro del tiempo de compilación. Para reutilizar este generador en los cuatro estados de la FSM, se recurre a un multiplexor de datos a la entrada y se controla mediante el controlador de eventos de la FSM. El multiplexor selecciona las entradas correctas para el generador de productos escalares en cada estado de la FSM. Los detalles del generador de productos escalares y el cumulador de coma flotante son similares a los del diseño de Cholesky y por tanto no se incluyen aquí.
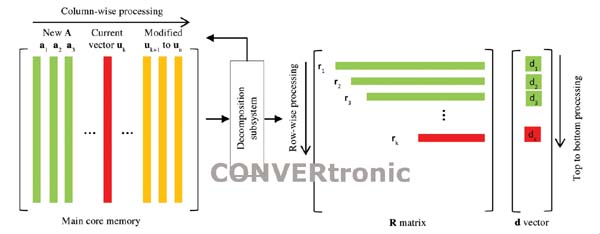
La memoria necesaria para la descomposición de QR se optimiza con la reutilización del bloque de memoria del núcleo principal que inicialmente contiene la matriz A y el vector de entrada b. El proceso tiene lugar en el sentido de la columna, de izquierda a derecha, en la memoria del núcleo. Una vez completada una columna y ya no se necesite, se reescribe con la columna correspondiente de una nueva matriz. En el momento en que se descomponga la antigua matriz A, el contenido original de este bloque de memoria se ve sustituido por una nueva matriz, manteniendo así la capacidad de proceso de la matriz de extremo a extremo y sin pausas.
En los primeros dos estados de la FSM, los elementos de la matriz R se generan elemento a elemento en el sentido de la fila y empezando por el elemento diagonal para cada fila. En el estado de sustracción de la FSM, las columnas de la matriz A en la memoria principal se actualizan de forma recursiva y se sustituyen por los vectores calculados parcialmente. Por ejemplo, en la columna k, todas las columnas k+1 a n se actualizan en la memoria al sustraer la versión escalada de de cada una de las columnas k+1 a n. Este proceso calcula de forma recursiva los vectores uk+1 a un y es una versión más eficiente e la ecuación (6) para la implementación del hardware. Al procesar en el sentido de la columna, en el cuarto estado de la FSM, cada uk nuevo calculado se multiplica con el vector de entrada b para generar un solo elemento dk del vector de columna d. La matriz Q no se genera de forma explícita pero se generan sus columnas ortogonales, uk, utilizadas en fases posteriores de la FSM, y se sobreescriben en la columna correspondiente, ak, de la nueva matriz en el siguiente ciclo de la FSM. La Figura 5 muestra la organización de la memoria y la secuencia de proceso del subsistema de descomposición QR.
Las salidas del primer subsistema son la matriz R y el vector de columna d. La matriz R es una matriz triangular superior y se genera en el sentido de la columna de izquierda a derecha como indican las ecuaciones (3) y (4). Se aplica una estructura de memoria triangular de tipo ping-pong. Mientras se procesa la sección triangular superior en el subsistema de sustitución regresiva, la sección triangular inferior se llena por medio del subsistema de descomposición, y viceversa. El vector de columna d se agrega a la matriz R y se genera en el sentido de la columna y de arriba hacia abajo. La salida de la sustitución regresiva es el vector solución x de las ecuaciones lineales Ax = b.
El solucionador QR se puede implementar es un formato multicanal parecido al solucionador de Cholesky para mejorar la utilización, reducir la latencia y aumentar al rendimiento del diseño. La mejora en el rendimiento se debe principalmente a la reducción efectiva de la latencia del acumulador de coma flotante.
3. Flujo de diseño y paquete de herramientas
Metodología de evaluación
Para esta evaluación, Altera suministró a BDTI las implementaciones de los solucionadores de Cholesky y QR creados mediante el DSP Builder Advanced Blockset. Altera proporcionó a los ingenieros de BDTI un PC con las herramientas de Altera y MathWorks ya instaladas. A continuación los ingenieros de BDTI examinaron los diseños de Altera, los simularon y sintetizaron, todo ello dentro del entorno Simulink. Además, los diseños sintetizados se aplicaron a dos dispositivos por separado: las FPGA Stratix V y Arria V. En el proceso, BDTI evaluó el flujo de diseño de Altera y las prestaciones de los dos ejemplos de diseño.
Dado que las tarjetas utilizadas para esta evaluación no podía generar los estímulos para los diseños de ejemplo, cada uno de éstos contiene un bloque de generación de estímulos implementado mediante bloques de DSP Builder Advanced Blockset y compilados con el diseño de la aplicación sometida a test. Para minimizar el impacto de bloque de estímulo sobre las prestaciones del diseño de test y el uso de recursos por parte de la FPGA, la matriz A se genera sobre la marcha por medio del bloque de estímulo a partir de un conjunto mucho más pequeño de datos aleatorios. Este pequeño conjunto de datos se genera por medio de scripts de archivos m en MATLAB, cargado en la memoria del bloque de estímulos y compilado con el diseño. Estos scripts de MATLAB utilizan el mismo algoritmo como el bloque de estímulos en el diseño de test para generar los datos de referencia del formato de coma flotante de doble precisión para el vector solución x con el fin de medir el nivel de error de los modelos Simulink y los diseños introducidos en las FPGA. En el diseño de Cholesky este algoritmo garantiza la definición positiva Hermitiana para la matriz A, mientras que el diseño con el solucionador de QR garantiza la creación de una matriz A bien acondicionada. Se implementaron cuatro configuraciones de tamaños de vector, matriz y canal para el diseño del solucionador de Cholesky, tres configuraciones en la FPGA Stratix V y dos configuraciones en el dispositivo Arria V, con una configuración común entre los dos. Para el diseño del solucionador QR se implementaron cuatro configuraciones para la FPGA Stratix V y dos de ellos también se implementaron en el dispositivo Arria V. Todas las configuraciones se evaluaron para la utilización de recursos de la FPGA, la máxima frecuencia de reloj, el rendimiento y su corrección funcional. Las restricciones al diseño de FPGA, como la frecuencia de reloj, la selección del dispositivo y el nivel de velocidad se especifican en el entorno Simulink.
Se evaluaron el rendimiento y las prestaciones a los niveles del modelo Simulink y de la plataforma de hardware. El modelo Simulink de ambos diseños se instrumenta para visualizar tanto el proceso progresivo como el total de los ciclos de proceso progresivo y regresivo, mientras que la ejecución del software Quartus II proporciona la Fmax alcanzada para cada configuración. Luego se descarga cada configuración en la plataforma de hardware, se ajusta su frecuencia de funcionamiento a Fmax y se inicia el proceso. Se capturan los vectores solución x de cada solucionador para cada configuración y se comparan con las correspondientes referencias de coma flotante de doble precisión generadas en MATLAB.
El script posterior a la simulación calcula la diferencia entre la salida de coma flotante de precisión sencilla Simulink IEEE 754 y los vectores de referencia de coma flotante de doble precisión generados en MATLAB. De forma parecida, el script calcula la diferencia entre la salida capturada de las simulaciones de hardware y las referencias de coma flotante de doble precisión generadas en MATLAB.
Evaluación del paquete de herramientas
Simulink está basado, y por tanto necesita, el entorno MATLAB. En el entorno Simulink, los diseños evaluados utilizan bloques del DSP Builder Advanced Blockset, que es un conjunto de bloques separado de la biblioteca estándar de DSP Builder. El DSP Builder Advanced Blockset está orientado hacia una implementación basada en bloque de los algoritmos y las rutas de datos de DSP, y utiliza un mayor nivel de abstracción que la biblioteca estándar de DSP Builder, que incluye bloques más generales y elementales. La biblioteca de DSP Builder Advanced Blockset contiene más de 50 funciones comunes de tipo trigonométrico, aritmético y booleano además de los bloques funcionales más complejos de la transformada rápida de Fourier (fast Fourier transform, FFT) y de filtros FIR. Son incorporaciones destacables a la versión 12.0 del software Quartus II su raíz cuadrada de baja latencia, el bucle for anidado y bloques de acumulador personalizable de coma flotante. Los elementos del Blockset estándar y de DSP Builder Advanced Blockset no se pueden mezclar en una estructura de ruta de datos al mismo nivel de jerarquía; solo los bloques de DSP Builder Advanced Blockset ofrecen soporte al compilador de coma flotante. Los bloques del Blockset estándar no están optimizados para el proceso de coma flotante. Además, si bien hay disponible la importación de HDL codificado a mano para el Blockset estándar, no está disponible en el DSP Builder Advanced Blockset dado que la herramienta no puede llevar a cabo implementaciones al nivel de HDL. En general, el método de introducción del diseño basada en bloques se adapta bien a los algoritmos de DSP; no obstante, debido a que no existen construcciones como case o switch en la biblioteca de bloques, resulta más intuitivo un método basado en texto para diseños de control intensivo y que incluyan máquinas de estado.
La puesta en marcha de una simulación con DSP Builder Advanced Blockset compila el modelo Simulink, genera código HDL y restricciones para el entorno de software Quartus II de Altera, genera un banco de test y archivos de script para el entorno ModelSim, y simula el modelo Simulink. El tiempo necesario para ejecutar las simulaciones para las diversas configuraciones osciló entre 3 minutos y 28 minutos dependiendo del tamaño de la matriz con un PC Intel Xeon W3550. La simulación Simulink genera estimaciones detalladas de la utilización de recursos sin necesidad de ejecutar la compilación del software Quartus II, ayudando así al diseñador a determinar con rapidez el tamaño del dispositivo necesario. Cuando se usa un kit de desarrollo de hardware, el usuario debe proporcionar la asignación de las patillas de salida en función del trazado de la tarjeta; el usuario puede aplicar las restricciones en las patillas de salida en el archivo .qsf suministrado en la carpeta del proyecto de software Quartus II para el diseño, o bien utilizar la configuración de patillas del software Quartus II para asignar y gestionar las patillas de salida desde un principio.
Se han realizado pruebas en el modelo para evaluar la facilidad de exploración el algoritmo y la generación de HDL correspondiente. Los parámetros de entrada, como el tamaño del producto escalar, el tamaño de la matriz y el tipo de datos se cambiaron el bloque de estímulos y la ejecución de la simulación. En todos los casos, se generó el código RTL correcto en unos minutos y los resultados de la simulación se ajustaban a la referencia de MATLAB.
Todas las configuraciones se sintetizaron mediante el software de diseño Quartus II, que se puede poner en marcha directamente desde el entorno Simulink. Un diseñador puede utilizar el software Quartus II en modo pulsar botón (push-button) con los parámetros de optimización por defecto o seleccionados por el usuario, o bien utilizar la herramienta Design Space Explorer (DSE). DSE, que forma parte del software Quartus II, ejecuta automáticamente múltiples pases del enrutador mediante una semilla diferente para cada pase. Se guarda la ruta con la mejor frecuencia de reloj. Se trata de un proceso automático que no exige la intervención del usuario pero necesita mucho más tiempo que el método pulsar botón, que con el software Quartus II tardó entre 1 y 6,5 horas dependiendo del tamaño del diseño.
El elevado nivel de abstracción aplicado por el flujo de diseño de DSP Builder Advanced Blockset permite acelerar los ciclos de exploración y simulación del espacio algorítmico, reduciendo así el tiempo total necesario para lograr un diseño final optimizado. Ahora bien, esta ventaja no es inherente a Simulink de la misma forma que, por ejemplo, la propagación el tipo de dato es inherente a Simulink. Para aprovechar las ventajas de exploración del espacio de diseño que ofrece el método de diseño basado en bloques respecto a RTL escrito a mano, es necesario que el diseñador dé otros pasos al crear el modelo Simulink. En concreto, el modelo se debe estructurar de forma que permita la exploración del espacio algorítmico en función de los parámetros. Para los ejemplos analizados en este artículo, se implementaron los modelos para permitir la realización de pruebas con diferentes tamaños de matriz, tamaños de vector y (en el caso del solucionador de Cholesky), el número de canales en paralelo. Una vez creado el modelo que incorpora este tipo de flexibilidad, se pueden explorar las estimaciones de prestaciones y de uso de recursos para varias configuraciones de diseño al variar estos parámetros. También es preciso conocer el diseño del hardware para lograr buenos niveles de rendimiento y de utilización de recursos, tal como ejemplifica el acumulador de coma flotante comentado en la Sección 2 de este artículo.
La formación para el flujo de diseño de DSP Builder Advanced Blockset cubre 4 horas de clases impartidas por Altera y aproximadamente 10 horas de seminarios y demostraciones en línea. Además, BDTI ocupó aproximadamente 90 horas estudiando la herramienta y ambos modelos en sesiones prácticas. El tiempo y el esfuerzo necesarios para manejar con agilidad el paquete de herramientas dependerá de la habilidad y de los conocimientos previos del diseñador.
Un ingeniero experimentado en el diseño basado en bloques de Simulink y en el diseño de hardware probablemente opinará que el método basado en DSP Builder Advanced Blockset es eficiente y de sencillo manejo. Para un diseñador de FPGA con pocos o ningún conocimiento de MATLAB y Simulink, el diseño con un mayor nivel de abstracción puede representar una nueva forma de pensar y por tanto una dificultad inicial, lo cual puede afectar a la curva de aprendizaje. Una vez familiarizado con la metodología, el diseñador puede conseguir ciclos de diseño notablemente más rápidos que con HDL. Se puede centrar en implementar el algoritmo sin preocuparse en detalles de diseño del hardware como la segmentación. El tiempo de diseño y verificación se ve reducido significativamente ya que la mayoría de la simulación y verificación funcional se lleva a cabo en el entorno Simulink. La salida RTL de la compilación de Simulink se puede ejecutar en el software ModelSim para una completa simulación funcional.
La curva de aprendizaje puede ser menos pronunciada para un ingeniero con conocimientos previos de diseño a nivel de sistema y escasa o nula experiencia en el diseño de hardware. Si bien el paquete de herramientas integra compilación de hardware, síntesis, enrutamiento y generación automática de script dentro del entorno Simulink y abstrae numerosos conceptos de diseño complejos como segmentación de datos y vectorización de señal, aún sigue siendo necesario cierto conocimiento sobre el hardware para completar una implementación.
(Continua en el mes de Abril)
Autor:
Por el equipo de Berkeley Design Technology, Inc. Octubre 2012
Más información o presupuesto
Articulos Electrónica Relacionados