


Inteligencia artificial que entiende las relaciones entre objetos


Cuando los humanos observan una escena, ven los objetos y las relaciones entre ellos. Encima de su escritorio, puede haber un ordenador portátil que está sentado a la izquierda de un teléfono, que está delante de un monitor de ordenador.
Muchos modelos de aprendizaje profundo tienen dificultades para ver el mundo de esta manera porque no entienden las relaciones entre los objetos individuales. Sin el conocimiento de estas relaciones, un robot diseñado para ayudar a alguien en una cocina tendría dificultades para seguir una orden como "coge la espátula que está a la izquierda de los fogones y colócala encima de la tabla de cortar."
En un esfuerzo por resolver este problema, los investigadores del MIT han desarrollado un modelo que entiende las relaciones subyacentes entre los objetos de una escena. Su modelo representa las relaciones individuales de una en una y luego combina estas representaciones para describir la escena global. Esto permite al modelo generar imágenes más precisas a partir de descripciones de texto, incluso cuando la escena incluye varios objetos que están dispuestos en diferentes relaciones entre sí.
Este trabajo podría aplicarse en situaciones en las que los robots industriales deban realizar intrincadas tareas de manipulación de varios pasos, como apilar objetos en un almacén o ensamblar electrodomésticos. Además, se acerca a la posibilidad de que las máquinas aprendan de su entorno e interactúen con él como lo hacen los humanos.
"Cuando miro una mesa, no puedo decir que hay un objeto en el lugar XYZ. Nuestras mentes no funcionan así. En nuestras mentes, cuando entendemos una escena, la entendemos realmente en función de las relaciones entre los objetos. Creemos que construyendo un sistema que pueda entender las relaciones entre los objetos, podríamos utilizarlo para manipular y cambiar nuestros entornos de forma más eficaz", afirma Yilun Du, estudiante de doctorado del Laboratorio de Ciencias de la Computación e Inteligencia Artificial (CSAIL) y coautor del artículo.
Du escribió el artículo junto con los autores principales Shuang Li, estudiante de doctorado del CSAIL, y Nan Liu, estudiante de posgrado de la Universidad de Illinois en Urbana-Champaign; así como Joshua B. Tenenbaum, profesor de desarrollo de carrera Paul E. Newton de Ciencias Cognitivas y Computación en el Departamento de Ciencias Cerebrales y Cognitivas y miembro del CSAIL; y el autor principal Antonio Torralba, profesor de Electrónica Delta de Ingeniería Eléctrica y Ciencias de la Computación y miembro del CSAIL. La investigación se presentará en la Conferencia sobre Sistemas de Procesamiento de la Información Neural en diciembre.
 Una relación a la vez
Una relación a la vez
El marco que han desarrollado los investigadores puede generar una imagen de una escena a partir de una descripción textual de los objetos y sus relaciones, como "Una mesa de madera a la izquierda de un taburete azul. Un sofá rojo a la derecha de un taburete azul".
Su sistema descompone estas frases en dos partes más pequeñas que describen cada relación individual ("una mesa de madera a la izquierda de un taburete azul" y "un sofá rojo a la derecha de un taburete azul"), y luego modela cada parte por separado. A continuación, esas piezas se combinan mediante un proceso de optimización que genera una imagen de la escena.
Los investigadores utilizaron una técnica de aprendizaje automático denominada modelos basados en la energía para representar las relaciones individuales de los objetos en la descripción de una escena. Esta técnica les permite utilizar un modelo basado en la energía para codificar cada descripción relacional y, a continuación, componerlas de forma que se infieran todos los objetos y relaciones.
Al dividir las frases en trozos más cortos para cada relación, el sistema puede recombinarlas de diversas maneras, por lo que es más capaz de adaptarse a descripciones de escenas que no ha visto antes, explica Li.
"Otros sistemas tomarían todas las relaciones de forma global y generarían la imagen de una sola vez a partir de la descripción. Sin embargo, estos enfoques fallan cuando tenemos descripciones fuera de la distribución, como las que tienen más relaciones, ya que estos modelos no pueden adaptarse de una sola vez para generar imágenes que contengan más relaciones. Sin embargo, al componer juntos estos modelos separados y más pequeños, podemos modelar un mayor número de relaciones y adaptarnos a combinaciones novedosas", afirma Du.
El sistema también funciona a la inversa: dada una imagen, puede encontrar descripciones de texto que coincidan con las relaciones entre los objetos de la escena. Además, su modelo puede utilizarse para editar una imagen reordenando los objetos de la escena para que coincidan con una nueva descripción.
Comprensión de escenas complejas
Los investigadores compararon su modelo con otros métodos de aprendizaje profundo a los que se les dieron descripciones de texto y se les encargó que generaran imágenes que mostraran los objetos correspondientes y sus relaciones. En todos los casos, su modelo superó a las líneas de base.
También pidieron a los humanos que evaluaran si las imágenes generadas coincidían con la descripción original de la escena. En los ejemplos más complejos, en los que las descripciones contenían tres relaciones, el 91 por ciento de los participantes concluyó que el nuevo modelo funcionaba mejor.
"Algo interesante que descubrimos es que, para nuestro modelo, podemos pasar de tener una descripción de relación a tener dos, o tres, o incluso cuatro descripciones, y nuestro enfoque sigue siendo capaz de generar imágenes que se describen correctamente con esas descripciones, mientras que otros métodos fallan", afirma Du.
Los investigadores también mostraron al modelo imágenes de escenas que no había visto antes, así como varias descripciones de texto diferentes de cada imagen, y fue capaz de identificar con éxito la descripción que mejor se ajustaba a las relaciones de los objetos en la imagen.
Y cuando los investigadores dieron al sistema dos descripciones de escenas relacionales que describían la misma imagen pero de forma diferente, el modelo fue capaz de entender que las descripciones eran equivalentes.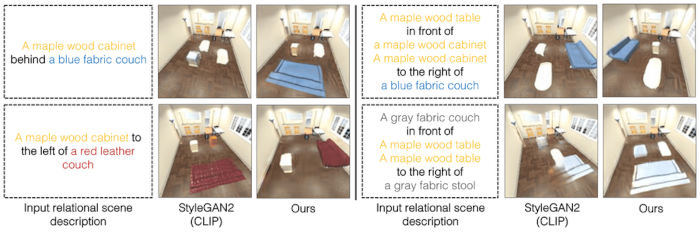
Los investigadores quedaron impresionados por la solidez de su modelo, especialmente cuando trabajaba con descripciones que no había encontrado antes.
"Esto es muy prometedor porque se acerca más a la forma de trabajar de los humanos. Los humanos sólo ven varios ejemplos, pero nosotros podemos extraer información útil de esos pocos ejemplos y combinarlos para crear infinitas combinaciones. Y nuestro modelo tiene esa propiedad que le permite aprender a partir de menos datos pero generalizar a escenas o generaciones de imágenes más complejas", afirma Li.
Aunque estos primeros resultados son alentadores, a los investigadores les gustaría ver cómo funciona su modelo en imágenes del mundo real más complejas, con fondos ruidosos y objetos que se bloquean entre sí.
También están interesados en incorporar su modelo a los sistemas robóticos, de modo que un robot pueda inferir las relaciones de los objetos a partir de los vídeos y aplicar este conocimiento para manipularlos en el mundo.
"El desarrollo de representaciones visuales que puedan hacer frente a la naturaleza compositiva del mundo que nos rodea es uno de los principales problemas abiertos en la visión por ordenador. Este trabajo supone un avance significativo en este problema al proponer un modelo basado en la energía que modela explícitamente múltiples relaciones entre los objetos representados en la imagen. Los resultados son realmente impresionantes", afirma Josef Sivic, destacado investigador del Instituto Checo de Informática, Robótica y Cibernética de la Universidad Técnica Checa, que no ha participado en esta investigación.
Esta investigación cuenta con el apoyo, en parte, de Raytheon BBN Technologies Corp., Mitsubishi Electric Research Laboratory, la National Science Foundation, la Office of Naval Research y el IBM Thomas J. Watson Research Center.
###
Escrito por Adam Zewe, MIT News Office
Articulos Electrónica Relacionados
- El CI acelerador de IA de Maxi... Maxim Integrated Products, Inc es el orgulloso ganador del prestigioso "embedded award 2021". Durante la celebración del Embedded World DIGITAL 2021, la empresa...
- Proyecto de fabricación de con... RS Components (RS), marca de Electrocomponents plc se ha asociado con BARTH® Elektronik GmbH, fabricante de controladores en miniatura, para desarrollar un senc...
- Chip que reduce el consumo de ... La mayoría de los avances recientes en sistemas de inteligencia artificial, tales como programas de reconocimiento de habla o rostro, han sido cortes&iac...
- Un modelo de IA acelera la vis... Un vehículo autónomo debe reconocer con rapidez y precisión los objetos que encuentra, desde un camión de reparto aparcado en la esquina hasta un ciclista que s...
- Dando a los vehículos autónomo... Los vehículos autónomos que dependen de sensores de imagen basados en la luz a menudo tienen dificultades para ver a través de condiciones de ceguera, como la...
- Nuevos materiales para mejorar... AIMPLAS, Instituto Tecnológico del Plástico, trabaja en el desarrollo de unos novedosos materiales plásticos que optimizan el almacenamiento de la energía prove...
- El mercado de las baterías de ... El rápido crecimiento del mercado de vehículos eléctricos ha impulsado el desarrollo, la fabricación y la venta de baterías, especialmente las de iones de litio...
- ABB y Talga explorarán las opc... La empresa de tecnología global ABB y la empresa de ánodos de baterías y aditivos de grafeno Talga Group han firmado un Memorando de Entendimiento para desarrol...
- Innovación en la fabricación s... El último informe de IDTechEx, "Sustainable Electronics Manufacturing 2023-2033", explora cómo puede reducirse el impacto medioambiental de la fabricación de pl...
- Un conjunto de nuevas aplicaci... Se prevé que el mercado emergente de semiconductores de potencia de carburo de silicio (SiC) y nitruro de galio (GaN) crezca en un factor de 17, durante los pró...
- La Comisión Europea define el ... El Plan de Recuperación Europea (Next Generation EU) tiene un objetivo claro: transformar el tejido productivo de Europa a partir de dos ejes, la digitalización...
- Estamos en un punto de inflexi... Los cambios en la industria del automóvil son un tema candente. Los avances tecnológicos están impulsando muchas tendencias y actualizaciones en los vehículos, ...













